LLMs and Databases
In his blog post, Mehul Shah asks:
So, what does this (LLMS) all mean for infrastructure like databases? I argue it has three implications:
First, the most prosaic implication is that we’ll need to build databases for LLMs. (Higher throughput)
The second and more interesting implication is that we will likely build databases with LLMs. (Rewrite/Custom Develop database code itself)
Finally, we will build all of our analytics engines (i.e. data warehouses) on LLMs and unstructured data will be first-class.
Here we argue that this is a LLM centric view with database as a junior partner trying to adjust itself to the changing reality. We will then present a database maximalist view and then outline ways in which LLMs and Databases can work together as equal partners to solve business problems.
Database Maximalism
LLMs are themselves a probabilistic graph database that won the hardware lottery. That’s a minor variation what Chaitanya Joshi argues here.
Pre-training can be seen as the process of creating a clustered index on the graph followed by a lossy compression of all leaf nodes, leaving only the index around. Key observation: original data is no longer is recoverable because of the lossy compression.
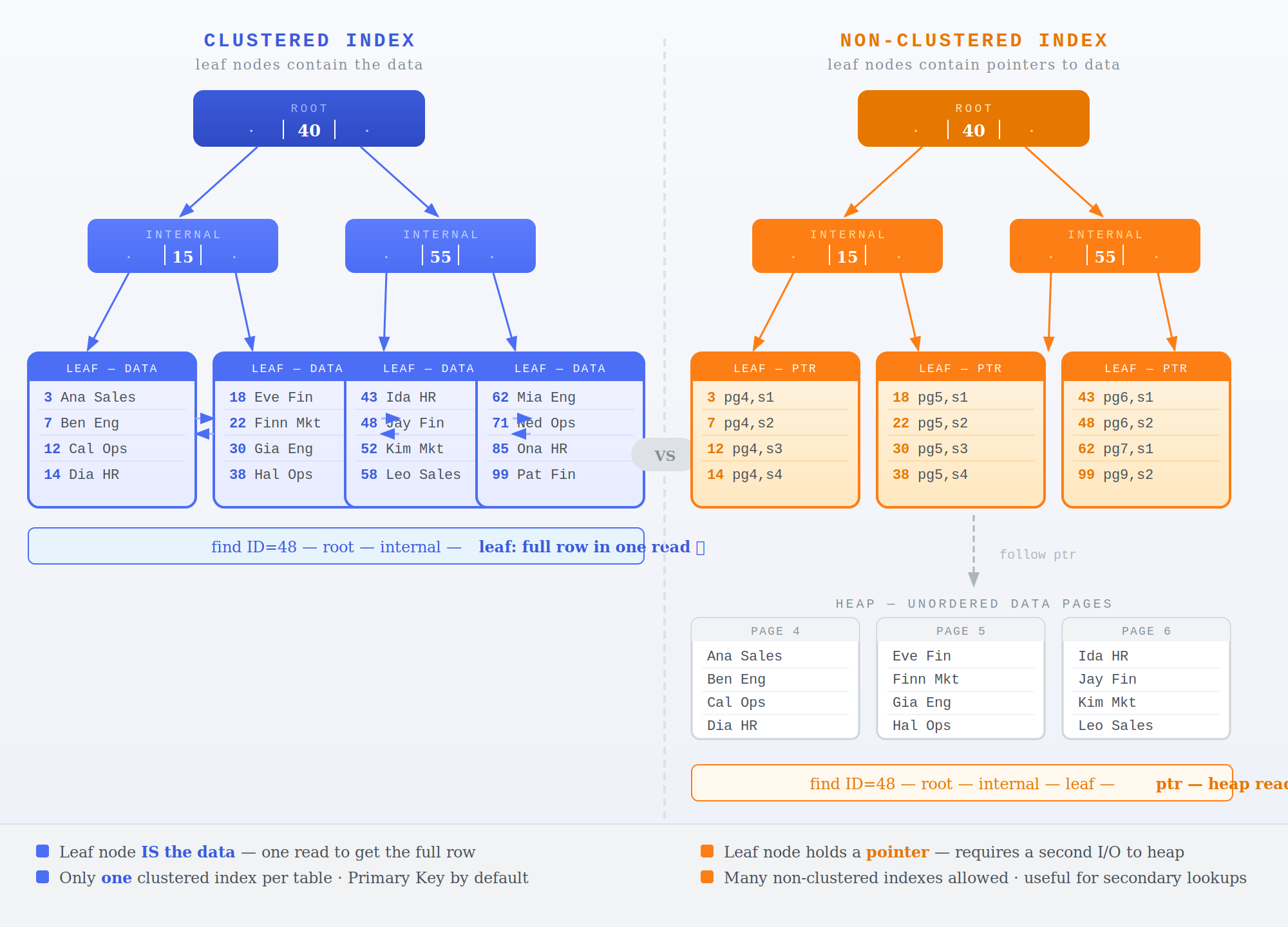
Lastly, Databases have had a history of using probabilistic data structures - bloom filters, sketches, skip lists and learned indices to speed up query processing. LLMs are the latest iteration of the same trend.
LLMs and Databases as equal partners
A healthier relationship is possible between these two fields. One is an established science and a major chunk of corporate spending on tech. The other is an upcoming star that is going to change the tech industry and everything adjacent to it.
A few ideas:
- LLMs are good at recognizing patterns. Use them to organize storage. Instead of throwing rows in a heap and building an index, organize storage based on what LLMs understand about it.
- LLMs as query planners - apart from the stats computed in the local db, we can bring world knowledge to pick query plans.
- LLMs and Databases can collaborate to bridge the probabilistic and deterministic, seamlessly switching between the two. One nice side effect of this is that RBAC (role based access control) becomes possible.
Other questions to ponder: the meaning of pre-training and continuous learning changes significantly with Database tech taking a more significant role vs today.